
Since 2000, ServerCentral Turing Group (SCTG) has evaluated countless technologies to identify the best possible solutions and business practices to help our customers and partners address all of the critical elements of their IT infrastructure. Now more than ever, questions about backup, replication and disaster recovery are top of mind.
Whether it’s supporting one company’s need to provide high-availability, always-on solutions, or helping another determine the right level of continuity for their business, these conversations won’t slow down any time soon.
The first thing we dive into is the company’s backup requirements.
What are your RTO & RPO objectives?
When we speak about Recovery Time Objectives (RTO), we’re typically speaking about the time required for the resumption of core IT activities after an issue has occurred.
When we speak about Recovery Point Objectives (RPO), we’re typically speaking about data-driven applications, where the data and the application process must stay in sync (eCommerce, for instance). In most instances, RPOs are assigned to applications that have direct revenue impact.
We ask these as two separate questions because the application and process requirements significantly differ with RTO and RPO.
What services are the easiest to prepare for and manage?
Anything virtualized/clustered/software with support for failure scenarios. Email, for example.
Which services are difficult to prepare for and manage?
Old/end-of-life software, homegrown or legacy apps not coded for redundancy, and physical servers with older OSs (which may have drivers for older hard drive interfaces, such as ATA or SCSI).
Do you need single-site or multi-site backups?
When single-site or multi-site backup is presented as the critical requirement, it’s important to note how applications, data, and VMs are backed up today. In many instances, backup processes vary wildly by application. Within multi-site organizations, the backup processes can vary significantly from site to site.
Where you back up is as important as what you back up.
Some companies back up locally, on site. Others back up to tapes, which are then stored off site.
While these are both strong starts, they fail to capitalize on managed solutions that are easily configured to deliver automated backups to a high-availability target at a high-availability data center.
Managed backup solutions provide backups of data, applications, and VMs, while offering the ability to quickly restore with live data from high-availability facilities in the event of an emergency.
Typically, big companies think they need big disaster recovery plans, while small companies think they have small backup requirements.
In our experience, a good disaster recovery plan completely depends on the revenue and operational implications of downtime.
It’s these values that dictate just how big or small your backup requirements should be — not your company size.
Replication
Once backup questions are answered, the next step is typically replication. Replication can mean many things: having multiple SANs in sync, keeping copies of images or file server backups available in multiple locations, and so on. Some companies address backup and replication in one step — but many don’t.
The critical aspect of replication is that it is happening in multiple, high-availability data centers on redundant, high-performance infrastructure.
As we continue talking about replication, we’re also talking about the need to accelerate the movement of data. Compression, deduplication, etc. all become critical pieces of the puzzle.
Deduplication
Deduplication specifically helps in a few places:
- On the backup client which prevents sending the data to the backup server twice;
- On the storage platform, to optimize the use of disk space; and
- By optimizing caching on reads.
For example, if a company’s servers use a common OS or a base image, they only need one copy in cache to optimize the resource and expedite recovery.
Network
Equally critical to the underlying storage infrastructure is the network infrastructure. We touched on this above regarding deduplication, but it is worth highlighting in a bit more detail as it is often overlooked as a critical success factor in BC/DR strategies.
As you can see here, there are very serious ramifications between a 1 GbE and a 10 GbE network connection when it comes to a restore operation:
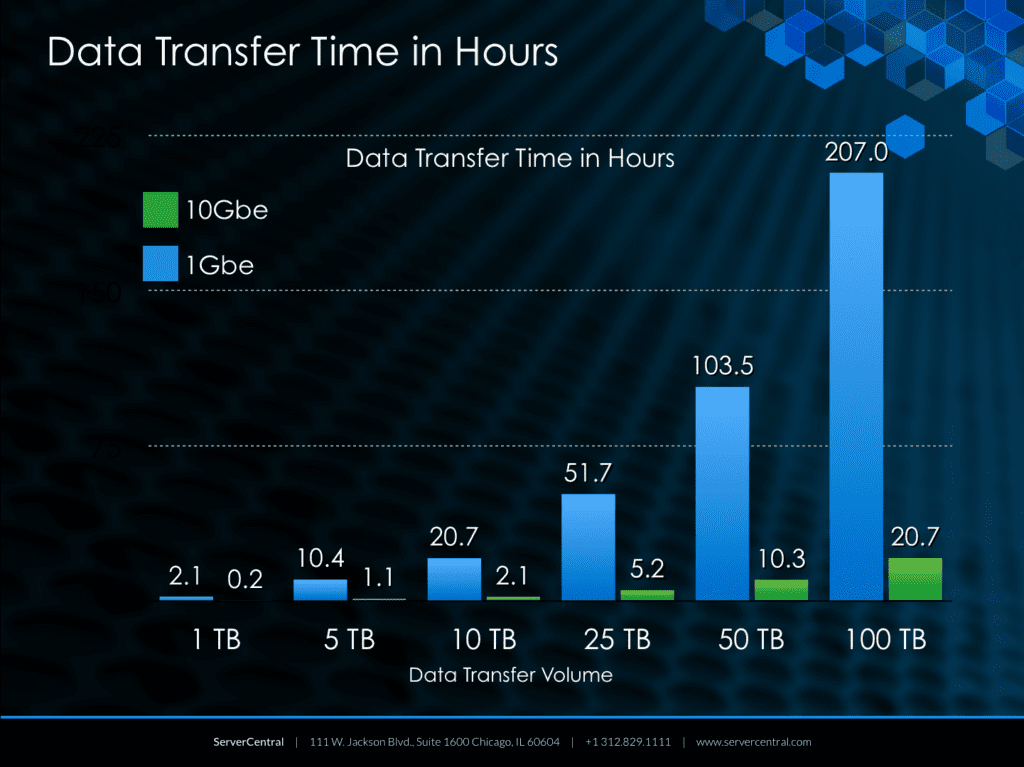
Note: These are best-case scenarios for a local transfer. Public, network-based transfers will see significant degradation in performance.
Disaster recovery
When we begin speaking about disaster recovery, in almost all cases, it is a much larger conversation. There are significant operational, compliance, and financial implications. There are some powerful solutions on the market from companies like Zerto that provide near active-active configurations, but they depend heavily upon the virtualization setup.
To make a very long story short, this is when the right people from your company and SCTG need to get to a whiteboard.
If you know SCTG, you know we’re always happy to share what we learn. Here’s a worthwhile trick we recommend to customers to address the bandwidth issue:
Configure VM restores directly to a DR infrastructure. With hypervisors ready to go at a DR site, simply boot the backup images and you’re back in business. These can be dedicated or shared compute and storage resources (depending upon your requirements).
Some good news
Today’s tech makes DR processes much less painful than they used to be.
It’s easy to get deep into technology architectures when discussing business continuity. However, it’s important to ground everything on the importance of each service to your business: What’s the cost of having each service down? What are acceptable recovery timeframes for each service?
Once these baselines are set and recognized across your organization, a decision can be made on how to back up, replicate, and restore the data.
Additionally, as more organizations write redundant, scalable software designed for cloud environments, and as more governments mandate DR testing for banks and other critical infrastructure, this BCDR technologies are going to be the norm for everyone.
When it’s time for you to start your own BCDR conversation, SCTG can help.
