One thing I like about vSphere 6.5 is that there are features that every vSphere environment, big or small, simple or complex, can use.
Higher Availability: vCenter
One of the big issues that many customers face when deploying vCenter is related to availability. After all, vCenter itself can be a single point of failure in many environments. While technologies like HA are designed to function without vCenter being available, many deployments need very high uptime for vCenter just to carry out day-to-day activities. vCenter Heartbeat was the old way of doing this, but that product is no longer offered by VMware.
With 6.5, VMware offers a new way of ensuring high uptime for vCenter itself: VCSA High Availability.
This is a VCSA-only technology (not surprising given VMware’s desire to move away from the Windows vCenter Server). It basically allows you to cluster multiple vCenters that are responsible for the same environment. This is an Active/Passive configuration that uses a back-end network to replicate the vPostgres data between the Active, Passive, and Witness appliances. The Witness, as you can probably guess, is there to prevent split-brain scenarios (which sounds a lot cooler than it is in practice).
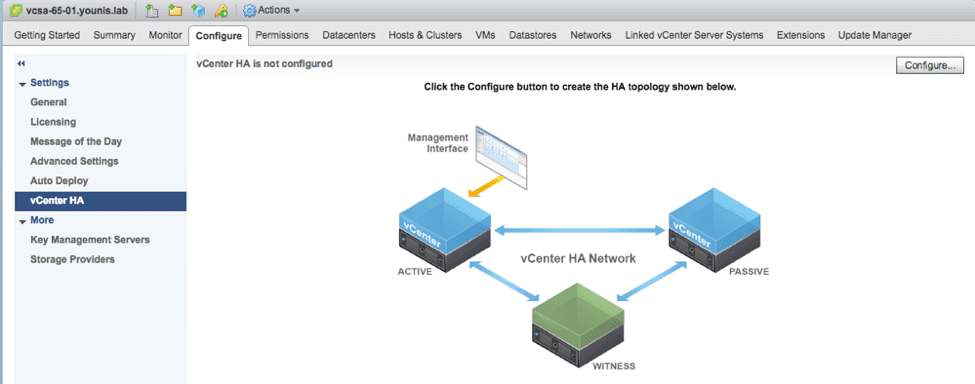
vCenter HA will go a long way in ensuring even higher uptime for vCenter. Given that things are becoming faster and more automated as a whole (and such automation would use vCenter to complete tasks), this is more important than ever to implement in modern environments.
While all of this vCenter stuff is great, what about improvements to normal VMs and workloads? VMware has made several improvements to their oldest feature in the book: High Availability.
Redundancy of the Future: Orchestrated HA, Proactive HA, and Admission Control
Orchestrated HA
One basic feature that is long overdue is the ability to set a restart order for an HA event. Consider this: Three servers (Database, Application, and Web) all service the same logical app. If you were to cold boot this app, you would probably have an order to the VMs to bring up, right? Usually it is something like Database first, then Application, and finally Web. Well, what if those three servers were all on the same physical host, and that host failed? Currently, HA will restart all three servers on different hosts. Unfortunately, while vSphere has traditionally had a very rudimentary VM Restart Priority, it doesn’t actually orchestrate any servers as they relate to each other. With 6.5, HA can bring up servers in a specific order (think vApps, SRM, or Zerto) after an HA event has occurred. This helps make failure events more predictable, and predictability is a great thing!
Proactive HA
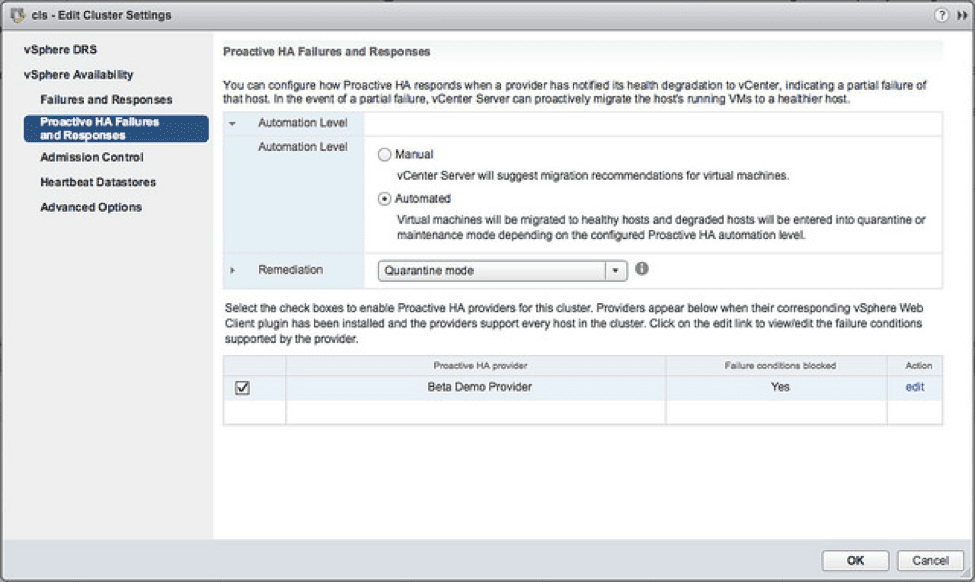
Also in the HA realm of upgrades, vSphere now has a new checkbox called Proactive HA. This is a third-party-dependent feature that enables hardware vendors to inform vSphere of potential issues with a host and trigger an HA event before the host actually begins showing signs of an issue. I can see definite use cases with this when it comes to things like SMART data from hard drives, flaky DIMMs, or even something like an overheating chassis.
This event will actually use vMotion to migrate the VMs (similar to putting a host into Maintenance Mode), thus preventing any downtime at all. This can also utilize a new status called Quarantine Mode, which keeps VMs from starting on this host unless absolutely necessary (or you can use a more traditional Maintenance Mode, which won’t put any VMs on the host no matter what).
Admission Control
The last of the big new HA features is a usability improvement focusing around Admission Control. Admission Control has long been a misunderstood and often improperly used feature, and in my opinion, is overdue for an overhaul. In previous versions of vSphere, it often felt like one of the features that was forgotten about from the 3.x days and never improved upon (fixed slot sizes notwithstanding). With 6.5, the VMware dev team has taken a more simplistic approach to Admission Control.
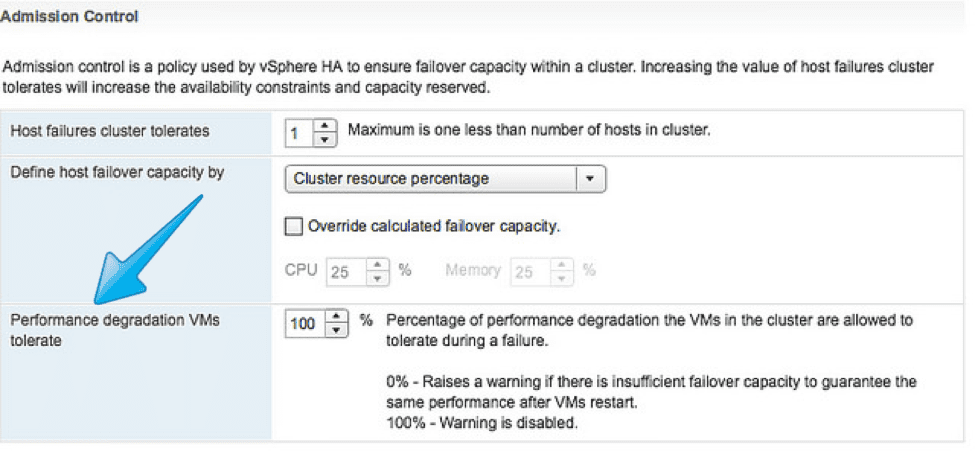
The long-time favorite of most vSphere admins has been Percentage based on resources used. In this setting, the admin sets a percentage of CPU and Memory that the cluster cannot go below, at which point it prevents the powering on of new VMs. This was done so that the existing VMs could still function should an HA event occur. Typically, this would be set to a percentage depending on the number of hosts in the cluster, designed for a single host failure. For example, if there were two hosts in the cluster, the percentage would be 50%, or ½. If you added a third host, the new ratio would be 1/3, or 33%, and so on. Prior to 6.5, this percentage would not update in the event of a host addition, so it was up to the admin team to ensure that the percentage was set properly (and let’s hope they could do fractions). That has all changed with 6.5: simply set the number of host failures you can tolerate, and it figures out the percentages for you.
The other huge issue with Admission Control was that it functioned strictly with reserved resources. If you didn’t set any reservations on a VM, then Admission Control would only care about the very small CPU and memory resources required. You could deploy many more machines than the cluster could actually support (assuming you’re running at 100%). For example, if you had a three-host cluster with 256 GB memory on each host, then you could really deploy 512 GB worth of VMs and still be at 100% with n-1 redundancy. Even with Admission Control on, if you didn’t reserve any resources, you could deploy many times that amount of resources and the VMs would still power on. They would just be incredibly slow because you would be swapping to disk constantly.
vSphere 6.5 has a new setting called Performance degradation VMs tolerate. This feature issues a warning when a host failure would cause a reduction in VM performance based on actual resource consumption, not just the configured reservations. By setting this to 0%, you can effectively change Admission Control to work for configured memory as opposed to reserved memory, and therefore the performance and not just the availability of the VMs can be preserved during an event.
My Take
I think these features will become staples in both new deployments and upgrades, as they are very easy to implement, accessible directly from the UI, and non-invasive to the VMs and overall vSphere environment. The benefits are significant and long overdue, and the costs (mainly an additional vCenter Server) are negligible for modern environments.
