Updated in January 2023
To summarize the last post, Preventing Data Loss with RAID, the various benefits of RAID include:
- protection against failure;
- larger volumes; and
- improved performance.
Now, let’s learn what each level of RAID means.
As with anything in engineering, there are several ways to go about this, each with its own set of trade-offs. If you have any questions or want to discuss this further, contact us.
RAID-0
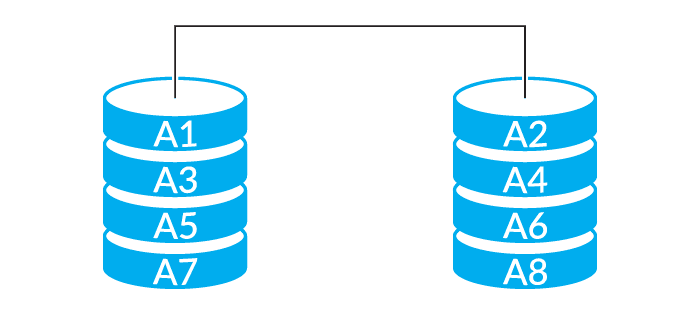
The most basic form of RAID is level 0 (these levels are typically expressed as RAID-#, so RAID-0, RAID-1, etc). RAID-0 stripes data across multiple drives. It writes the first block to the first drive, second to the next, and so on, until it hits all of the drives, then comes back to the first drive. This means you see the full performance of your drives since they’re all working in parallel, with essentially no overhead. The downside is there is no redundancy; any drive failure will cause complete data loss across all drives. So while this allows expanding storage and extremely high performance, it’s actually less reliable than a single drive.
Continuity, Disaster Recovery & AWS
RAID-1
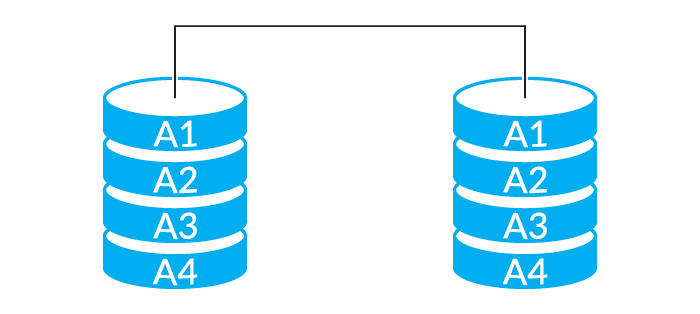
The next-simplest RAID level uses mirroring. This takes all data written to one drive and writes it in parallel to a second drive. This provides the highest redundancy since there is a 1-for-1 copy of all data written. It also provides very high read performance, as both disks can be read in parallel. Write performance is unaffected as although there are two disks writing in parallel, they’re writing the same data twice. The downside to RAID-1 is the high cost, as one must build out twice the capacity that’s actually required. Traditional RAID-1 is also designed for exactly two drives, and as such is limited in how far it can expand storage.
RAID-10
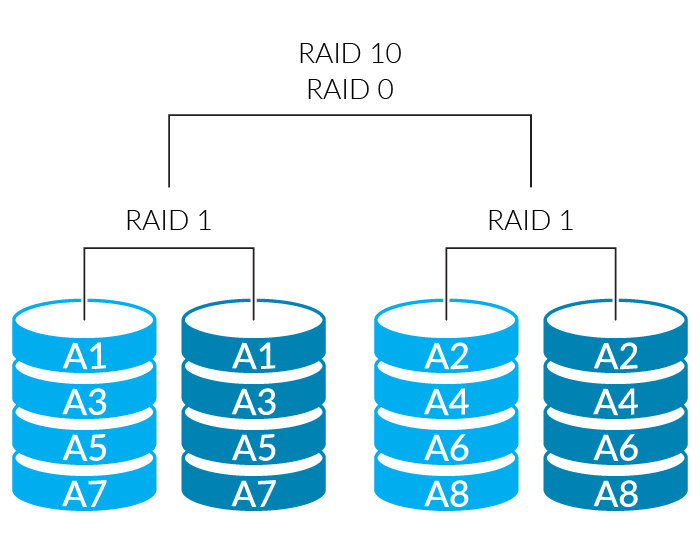
Addressing the lack of expandability of RAID-1, RAID-10 combines the approaches of RAID-1 and RAID-0. First, disks are mirrored into pairs, providing the high redundancy and high read performance of RAID-1. Then all of these pairs are striped using RAID-0, allowing it to expand across more than two drives, and also improving write performance. This is considered the gold standard for high-performance, high-reliability, high-capacity systems, although like RAID-1 it’s very expensive to implement as half of the capacity is used for the mirror. RAID-10 requires an even number of disks, and at least 4 disks in the RAID set (even since it’s built from RAID-1 pairs of disks, and a minimum of 4 since two pairs are the minimum that can be striped).
RAID-5
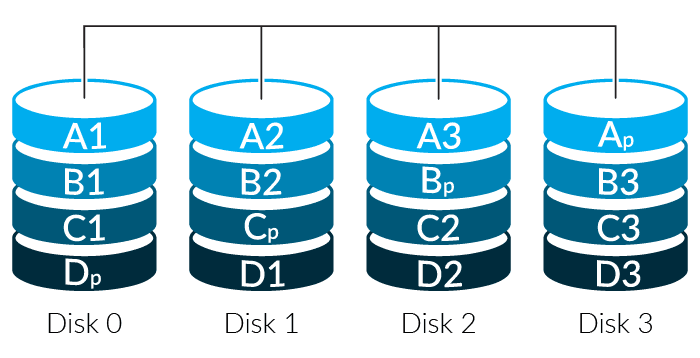
RAID-5 introduces the concept of parity to provide redundancy. Rather than write a complete duplicate of data to a second drive, it runs a fast algorithm across the same block on several disks and mathematically creates a new block based on them. Much as you can look at “5 + 2 + x = 10” and determine that x is “3”, when a drive fails a RAID controller can look at the remaining disks and reconstruct the missing data bit-by-bit.
RAID-5 supports single parity, so any drive in the array can fail and it can still function and rebuild the data. Parity information is spread across the drive set to even out access patterns and improve performance. This provides high storage capacity since not as many drives are devoted to redundancy, decent robustness as any drive can fail, and middling performance. Performance is impacted by the calculations necessary to read and write the data and reduces the parallelism that can be employed compared to RAID-0 and RAID-1.
RAID-6
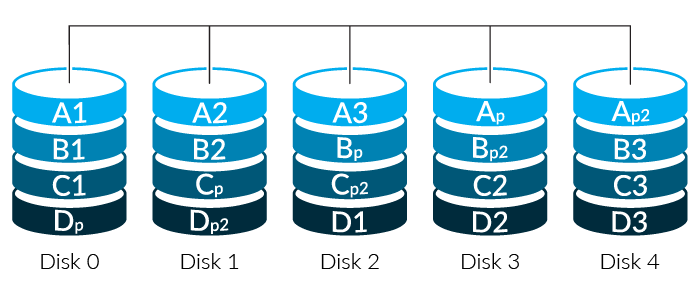
While RAID-5 protects against a single drive failing and can rebuild it, RAID-6 uses two different sets of parity calculations and can rebuild an array even with two simultaneous failures (what’s known as N+2 redundancy). RAID-6 requires at least 4 drives – at least two for data, and two for the parity information. RAID-6 makes the most sense when used with more disks — up to a point. While the efficiency rises with the number of disks, so does the chance of multiple failures and the complexity of rebuilding the disk set. RAID-6 has a good balance of capacity, redundancy, and performance, which makes it the workhorse of high-capacity storage.
Note: Missing something? We skipped over RAID levels 2 through 4, as these were variants on striping and parity-based redundancy, and largely superseded by RAID-5. They aren’t supported by modern RAID controllers. It’s highly unlikely you’ll see them in practice.
Rebuilding
When any redundant RAID system has a drive fail, it has to reconstruct the data once the failed drive is replaced. As drives get larger this takes longer. While the drive is rebuilding the array isn’t at full redundancy; it’s described as being degraded. While an array is in a degraded state it typically has less or no redundancy, performance is reduced sharply, and drives are under stress as they provide the data for the rebuild. Mirroring systems aren’t affected as badly, since only a single disk is required to rebuild the mirrored drive, but on parity-based systems like RAID-5 and RAID-6, performance typically drops significantly as data must be reconstructed on the fly via parity calculations.
As drive sizes increased, RAID-5 rebuild times followed, taking hours or even days to reconstruct the data from a lost drive. During this time disks were run full-tilt as the RAID controller recreated the missing drive (compare to RAID-1 or RAID-10 which only needs to look at a single drive to rebuild). This led to an issue of similar failure rates between drives in the same manufacturing lot. Typically the drives for a RAID set are bought together and will come from the same manufacturing lot – which means they have similar failure characteristics. Since all of the drives in the array operate as a set, once one drive fails it’s not uncommon to have another marginal drive in the same set. RAID-6 was created to address the shortcomings of RAID-5 as drive capacity grew, and provides protection against this by allowing for two simultaneous failures.
Wrapping Up
- RAID-10 has the best performance and redundancy characteristics but halves the usable capacity, which can make it expensive to deploy at scale. Sometimes this will be referred to as RAID-1, even though technically RAID-1 refers to only two disks. Provides 2N redundancy, wherein up to half the disks could fail (although you’d have to be lucky as to precisely which disks). RAID-1 and 10 are useful when you need very high performance and reliability, and are commonly seen on OS/boot drives and high-performance application servers.
- RAID-6 is typically used when a large amount of storage is required and there are a large number of disks in play. Provides N+2 redundancy. RAID-6 is commonly used inside large-scale storage products from EMC, IBM, and others for its high capacity and fault tolerance, although it is frequently supplemented by caching or SSD to mask performance issues. RAID-5 and 6 are useful when you have a large amount of data that needs to be redundant. Commonly seen on databases and large storage shelves.
- RAID-0 is seldom seen in the enterprise due to a complete lack of redundancy (a single drive failure will lose the whole array), but in specific cases, you may want to consider it. For instance, it can be useful for caching servers, where the stored data is unimportant, trivially replaceable, and high performance is critical.
RAID Level |
Redundancy |
Capacity |
Read Performance |
Write Performance |
| 0 | None | All drives | Excellent | Excellent |
| 1 / 10 | 2N | 50% of all drives | Excellent | Decent |
| 5 | N+1 | All but one drive | Decent | Variable |
| 6 | N+2 | All but two drives | Decent | Variable |
Want to rid your business of RAID woes?
We can take care of it for you. Schedule a 15-minute call with our RAID team — we’d love to meet you.
